Redis Data Integration architecture
Redis Data Integration (RDI) is a product that helps Redis Enterprise users ingest and export data in near real time.
- End to end solution; no need for additional tools and integrations
- Capture Data Change (CDC) included
- Covers most popular databases as sources and targets
- Declarative data mapping and transformations; no custom code needed
- Data delivery guaranteed (at least once)
- Zero downtime day two operations (reconfigure and upgrade)
RDI currently supports two use cases:
- Ingest (cache prefetch)
- Write-behind
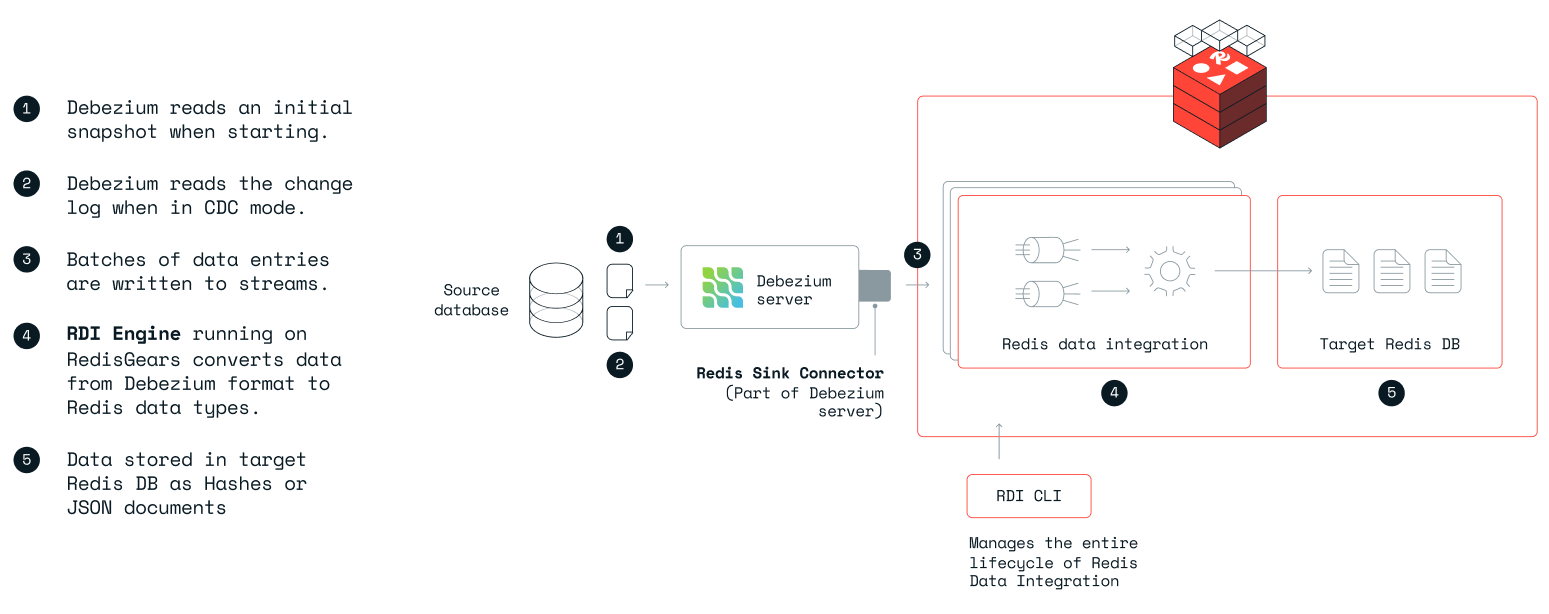
Ingest functionality and architecture
You can think of RDI Ingest as a streaming ELT process, where
- Data is Extracted from the source database using Debezium Server connectors
- Data is then Loaded into RDI, a Redis database instance that keeps the data in Redis streams alongside required metadata.
- Data is then Transformed using provided RedisGears recipes and written to the target Redis database.
RDI using Debezium Server works in two modes:
- Initial sync - where a snapshot of the entire database or a subset of selected tables is used as a baseline. The entire dataset is streamed to RDI and then transformed and written into the target Redis database.
- Live updates - where Debezium captures changes to the data that happen after the baseline snapshot and streams them to RDI where they are transformed and written to the target.
Supported data transformations
Mode mapping
RDI supports conversion of a database record into the following Redis types:
Each column in the record is automatically formatted as a number or string. See the data types list for the exact mappings.
Additional transformations
RDI supports declarative transformations to further manipulate the data, including denormalization of data from several records into a single JSON key in Redis. To learn more, see the data transformation section.
Architecture and components

Feeders
Debezium Server has a Redis sink that writes data and state to RDI streams. RDI also works with Arcion, a commercial CDC that provides an additional set of sources.
Redis data integration data plane
RDI data streams
RDI receives data using Redis streams. Records with data from a specific database table are written to a stream with a key reflecting the table name. This allows a simple interface to RDI, and it keeps the order of changes as served by Debezium.
RDI engine
RDI engine is built on top of RedisGears. It has two main logical functions:
- Transformation of data. In the current version, RDI only supports Debezium type conversion to Redis types, but future versions will support Apache Avro. In addition, there is a plan to provide data mapping between a denormalized relational model and denormalized Redis JSON documents.
- Writing data. This is the part where RDI writes the data to the target, ensuring order and guaranteeing at least once to prevent data loss. In addition, the writer can be configured to ignore, abort, or keep rejected data entries.
RDI control plane
RDI CLI
RDI comes with a Python-based CLI that is intuitive, self explanatory, and validating, to ease the entire lifecycle of RDI setup and management.
RDI configuration
RDI configuration is persisted at the cluster level. The configuration is written by the CLI deploy command, reflecting the configuration file. This mechanism allows for automatic configuration of new shards when needed, and can survive shard and node failure.
Secrets handling
RDI requires the following secrets:
- The RDI engine requires credentials and a certificate to connect and write encrypted data to the target Redis database.
- The Debezium Redis Sink Connector requires credentials and a certificate to connect and write data into the RDI database.
- The Debezium Source Connector requires the source database secrets.
- The RDI CLI requires a certificate to connect to the Redis Enterprise cluster. For the
createcommand, it requires the credentials of a privileged user but it does not cache or store these credentials.
Credentials and certificates can be served in one of the following ways:
- Entered manually as parameters to a CLI command (where applicable).
- Stored in environment variables.
- Injected to the temp file system by a secret store agent such as HashiCorp Vault.
Scalability and high availability
RDI is highly available:
- At the feeder level: Debezium Server is deployed using Kubernetes or Pacemaker for failover between stateless instances, while the state is secured in Redis.
- At the Data and Control Plane: Using Redis Enterprise mechanisms for high availability (shard replica, cluster level configurations, and so on).
RDI is horizontally scalable:
- Table level data streams can be split across multiple shards, where they can be transformed and written to the target in parallel, all while keeping table level order of updates.
Tested topologies
RDI runs on Redis Enterprise. It works on any installation of Redis Enterprise, regardless of the runtime environment (bare metal, VMs, or containers). RDI can be collocated with the target Redis database or it can be run on a different Redis Enterprise cluster.
Debezium Server should run in a warm, high availability topology, like one of the following:
- Running on two VMs in an active/passive setup. The failover orchestration can be done by tools such as Pacemaker.
- Running as a Kubernetes pod where Kubernetes watches the pod's liveliness and readiness, and acts to recover a nonfunctional pod. It is important to note that RDI does not keep any state on Debezium. All state is kept in RDI.
Write-behind functionality and architecture
RDI write-behind allows integration between Redis Enterprise (as the source of changes to data) and downstream databases or datastores. RDI captures the changes to a selected set of key patterns in a Redis keyspace and asynchronously writes them in small batches to the downstream database, so the application doesn't need to take care of remodeling the data or managing the connection with the downstream database.
RDI write-behind can normalize a key in Redis to several records in one or more tables at the target. To learn more about write-behind declarative jobs and normalization, see the write-behind quick start guide
Write-behind topology
RDI's CLI and engine come in one edition that can run both ingest and write-behind. However, the topology for write-behind is different. RDI engine is installed on a Redis database containing the application data and not on a separate staging Redis database. RDI streams data and control plane adds a small footprint of few hundreds of MBs to the Redis database. In the write-behind topology, RDI processes in parallel on each shard and establishes a single connection from each shard to the downstream database.
Model translation
RDI write-behind can track changes to the following Redis types:
Unlike the ingest scenario, write-behind has no default behavior for model translation. It is up to the user to create a declarative job, specifying the mapping between Redis keys and target database records.
The job keys and mapping sections help make this an easy task.